Advanced DevOps: Platform Test Matrix with Azure Pipelines
In my last article we started to dive into Azure Pipelines to build and run unit tests for a simple Sprint Boot application. Time to make the next step in our journey in Advanced DevOps.
In the Advanced DevOps series, I cover topics from continuous integration to continuous delivery, and monitoring. Let's go beyond build and test!
Today, we will look at testing against platforms that an application might need to support. From databases, to operating systems, to message brokers, to (Java) runtimes.
To do so we will leverage several Azure Pipelines' capabilities to go beyond our basic start from last time. That is:
I am lazy. So I have not produced a new sample app to demonstrate the platform tests but will use Eclipse hawkBit instead. hawkBit is a Java Spring based IoT application that supports a variety of databases and has a messaging component as well. It supports two Java runtime environments at this point.
Overall, my goal is to create a pipeline to test the platform variations of:
- OpenJDK: We will build and run tests against H2 database with OpenJDK 8 (hawkBit's main JRE) and OpenJDK 11.
- Furthermore, static code analysis with SonarCloud with a custom Quality Gate and Profile only on the OpenJDK 11 job. It will include integration tests against RabbitMQ latest to have the test coverage in the sonar analysis.
- RabbitMQ: We will run tests with H2 against three RabbitMQ versions on the OpenJDK 8 build.
- Databases: We will run tests against multiple versions of MySQL, SQL Server, and PostgreSQL on the OpenJDK 8 build.
With these I will not cover every variant that hawbBit users may have in production. That is mostly the case as the matrix will get too big otherwise.
We must be smart, and the trick is to cover the basics, i.e., every platform at least once, with some assumption on which combinations have value. For instance, to combine RabbitMQ versions and various database variants does not have much value as they have almost no impact on each other.
However, at the same time I decided that I can afford some overlap for more transparency in case of failure. Technically the OpenJDK 11 build overlaps with one of the RabbitMQ builds but it looked cleaner that way. The H2 Database did not get the same honor of a dedicated run as hawkBit is supporting this one for testing purposes only.
So, let's get started.
OpenJDK
In the pipeline below we select our Agent pool and three variables to configure the SonarCloud integration. What I define here are three defaults and a variable group as well. This way users can customize/override the variables at runtime without the need to edit the yaml itself.
This is useful for public community projects, so that members can leverage the yaml and parametrize it to their own needs at runtime without needing to edit it which would be messing up their GIT workflow.
Next, we come the two OpenJDK builds. Here we introduce two templates which is Azure Pipelines mechanism for re-usable content.
1pool:
2 vmImage: "ubuntu-18.04"
3
4variables:
5 - name: sonarCloudConnection
6 value: 'hawkBitSonar'
7 - name: sonarCloudOrganization
8 value: 'hawkbit'
9 - name: sonarProjectKey
10 value: 'org.eclipse:hawkbit'
11 - group: hawkbit
12
13jobs:
14 - job: JDK_11
15 displayName: Verify with JDK-11 and SonarCloud analysis
16 steps:
17 - template: rabbitmq-template.yml
18 - template: maven-template.yml
19 parameters:
20 mavenGoals: "verify -Dsonar.host.url=https://sonarcloud.io -Dsonar.organization=$(sonarCloudOrganization) -Dsonar.projectKey=$(sonarProjectKey)"
21 jdkVersionOption: "1.11"
22 sonarQubeRunAnalysis: true
23 sonarCloudConnection: $(sonarCloudConnection)
24 sonarCloudOrganization: $(sonarCloudOrganization)
25 - job: JDK_8
26 displayName: Build with JDK-8 (hawkBit default)
27 steps:
28 - template: maven-template.yml
29 parameters:
30 mavenGoals: "install license:check"
The first one is for Maven and SonarCloud. The templates follow the know syntax, but they can in addition define parameters as input interface. The boolean sonarQubeRunAnalysis is used both as a condition for the prepare task and as input for the maven task to run the sonar analysis.
The rest is standard with the exception that I put the JDK in the cache key to ensure that parallel running OpenJDK 8 & 11 jobs will not interfere with each other.
1parameters:
2 - name: mavenGoals
3 displayName: Maven Goal
4 type: string
5 - name: jdkVersionOption
6 displayName: JDK Version
7 type: string
8 default: "1.8"
9 - name: sonarQubeRunAnalysis
10 displayName: Enable SonarQube analysis
11 type: boolean
12 default: false
13 - name: sonarCloudConnection
14 displayName: Optional SonarCloud connection
15 type: string
16 default: ''
17 - name: sonarCloudOrganization
18 displayName: Optional SonarCloud organization
19 type: string
20 default: ''
21 - name: mavenCacheFolder
22 displayName: Maven Cache Folder
23 type: string
24 default: $(Pipeline.Workspace)/.m2/repository
25
26steps:
27- task: SonarCloudPrepare@1
28 condition: eq('${{ parameters.sonarQubeRunAnalysis }}', true)
29 displayName: 'Prepare SonarCloud analysis configuration'
30 inputs:
31 SonarCloud: ${{ parameters.sonarCloudConnection }}
32 organization: ${{ parameters.sonarCloudOrganization }}
33 scannerMode: Other
34- task: Cache@2
35 inputs:
36 key: 'maven | "$(Agent.OS)" | "${{ parameters.jdkVersionOption }}" | **/pom.xml'
37 path: ${{ parameters.mavenCacheFolder }}
38 displayName: Cache Maven local repo
39- task: Maven@3
40 inputs:
41 mavenPomFile: "pom.xml"
42 mavenOptions: "-Xmx3072m"
43 javaHomeOption: "JDKVersion"
44 jdkVersionOption: ${{ parameters.jdkVersionOption }}
45 jdkArchitectureOption: "x64"
46 publishJUnitResults: true
47 sonarQubeRunAnalysis: ${{ parameters.sonarQubeRunAnalysis }}
48 sqMavenPluginVersionChoice: 'latest'
49 testResultsFiles: "**/surefire-reports/TEST-*.xml"
50 goals: "${{ parameters.mavenGoals }} -Dmaven.repo.local=${{ parameters.mavenCacheFolder }}"
The RabbitMQ template is even simpler. Not much to say here:
1parameters:
2 - name: rabbitmqVersion
3 displayName: RabbitMQ Version
4 type: string
5 default: "3.8"
6
7steps:
8 - script: docker run -d --name rabbit -p 15672:15672 -p 5672:5672 -e RABBITMQ_DEFAULT_VHOST=/ rabbitmq:${{ parameters.rabbitmqVersion }}-management
9 displayName: "Setup RabbitMQ docker instance"
RabbitMQ
Using this template, we have now everything in place to run our RabbitMQ matrix as well. What is interesting here is the matrix strategy to inject the versions into the template.
The matrix jobs can be capped. If this is not done like here, Azure Pipelines will scale out until the agent pool size of the organization is maxed out (again, ten for public projects).
Next, we use dependsOn and thesucceeded() condition to leverage the cache already built by the OpenJDK 8 run and make sure not to run all these expensive platform integration tests if the basic build has already failed.
1- job:
2 dependsOn: JDK_8
3 condition: succeeded()
4 displayName: RABBIT
5 strategy:
6 matrix:
7 3.6:
8 rabbitmqVersion: "3.6"
9 3.7:
10 rabbitmqVersion: "3.7"
11 3.8:
12 rabbitmqVersion: "3.8"
13 steps:
14 - template: rabbitmq-template.yml
15 parameters:
16 rabbitmqVersion: $(rabbitmqVersion)
17 - template: maven-template.yml
18 parameters:
19 mavenGoals: "verify"
Databases
The databases go into a similar direction as RabbitMQ, by means of starting the database in a Docker container. The credentials and settings are injected by command line into the maven build.
1- job:
2 dependsOn: JDK_8
3 condition: succeeded()
4 displayName: MYSQL
5 strategy:
6 matrix:
7 5.6:
8 dbVersion: "5.6"
9 5.7:
10 dbVersion: "5.7"
11 steps:
12 - template: rabbitmq-template.yml
13 - script: "docker run --name mysql -p 3306:3306 -e MYSQL_ROOT_PASSWORD=8236472364 -e MYSQL_DATABASE=hawkbit -d mysql:$(dbVersion)"
14 displayName: "Setup MYSQL Database docker instance"
15 - template: maven-template.yml
16 parameters:
17 mavenGoals: "verify -Dspring.jpa.database=MYSQL -Dspring.datasource.driverClassName=org.mariadb.jdbc.Driver -Dspring.datasource.url=jdbc:mysql://localhost:3306/hawkbit -Dspring.datasource.username=root -Dspring.datasource.password=8236472364"
18 - job:
19 dependsOn: JDK_8
20 condition: succeeded()
21 displayName: MSSQL
22 strategy:
23 matrix:
24 2017:
25 dbVersion: "2017-latest"
26 2019:
27 dbVersion: "2019-latest"
28 steps:
29 - template: rabbitmq-template.yml
30 - script: |
31 docker run --name mssql -p 1433:1433 -e ACCEPT_EULA=Y -e SA_PASSWORD=1234567890.Ab -d mcr.microsoft.com/mssql/server:$(dbVersion)
32 until [ "`/usr/bin/docker inspect -f {{.State.Running}} mssql`" == "true" ]; do sleep 1; done
33 sleep 120
34 until docker exec mssql /opt/mssql-tools/bin/sqlcmd -S localhost -U SA -P "1234567890.Ab" -Q "CREATE DATABASE hawkbit"; do sleep 1; done
35 displayName: "Setup MSSQL Database docker instance"
36 - template: maven-template.yml
37 parameters:
38 mavenGoals: "verify -Dspring.jpa.database=SQL_SERVER -Dspring.datasource.url=jdbc:sqlserver://localhost:1433;database=hawkbit -Dspring.datasource.username=SA -Dspring.datasource.password=1234567890.Ab -Dspring.datasource.driverClassName=com.microsoft.sqlserver.jdbc.SQLServerDriver"
39 - job:
40 dependsOn: JDK_8
41 condition: succeeded()
42 displayName: POSTGRESQL
43 strategy:
44 matrix:
45 12:
46 dbVersion: "12"
47 13:
48 dbVersion: "13"
49 steps:
50 - template: rabbitmq-template.yml
51 - script: "docker run --name postgres -p 5432:5432 -e POSTGRES_PASSWORD=1234567890 -e POSTGRES_DB=hawkbit -d postgres:$(dbVersion)"
52 displayName: "Setup POSTGRESQL Database docker instance"
53 - template: maven-template.yml
54 parameters:
55 mavenGoals: "verify -Dspring.jpa.database=POSTGRESQL -Dspring.datasource.url=jdbc:postgresql://localhost:5432/hawkbit?currentSchema=hawkbit -Dspring.datasource.username=postgres -Dspring.datasource.password=1234567890 -Dspring.datasource.driverClassName=org.postgresql.Driver"
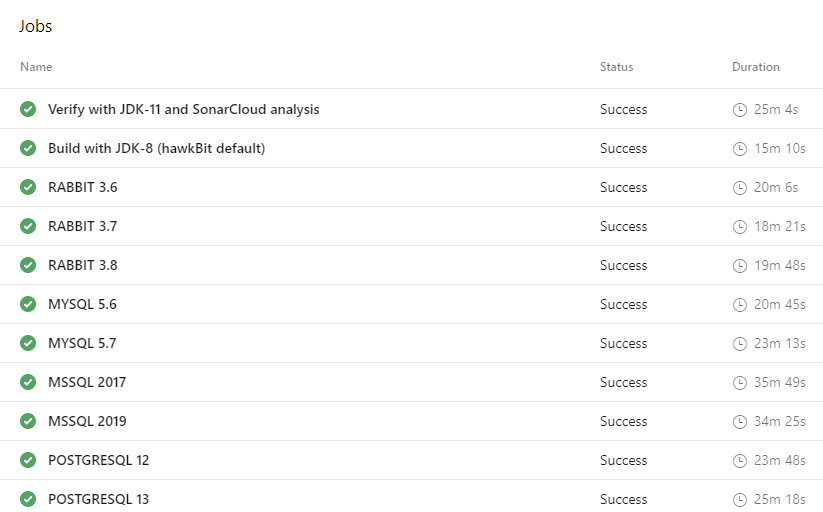
Here we have it! Overall, 11 Jobs covering the various platforms with a combined runtime of 51 minutes. My 12 core 6-month-old desktop PC has similar times per individual job btw. Not too shabby for a free offering. My favorite play toy Azure delivered...again.
Next steps
As mentioned in the introduction I plan to make this a series where we are going to dive deeper into the magic of DevOps technologies article by article. So, the best next step I recommend is to wait for my next article.
As always, the code of this example is over at GitHub.